Data på genom-nivå og likhets-myten
(Fritt etter 'More than a Monkey', Jeffrey Tomkins, PhD; Kap. 2)
Nylig forskning i den moderne genom-epoken, som benytter tilfeldige, aktuelle DNA-sekvenser, har i mange tilfeller tilsynelatende tilpasset seg til det tidlige høy-likhets dogme, etablert ved 'reassociation kinetics' se kap.1. Den høye DNA-likheten mellom aper og mennesker, som tilsynelatende ble etablert ved 'reassociation kinetics' forskning, etablerte en uutalt 'gull-standard' for vitenskaps-samfunnet. DNA-sammenlignings prosjekter mellom menneske og sjimpanse, viser seg å benytte en rekke trick og teknikker for å unngå ulike data, og bare fokusere på regioner som var meget like. Hensikten var å få sjimpanse-DNA til å virke enda mer sammenlignbar og menneske-lik.
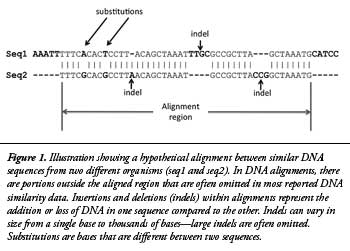
En av nøklene til å forstå menneske-sjimpanse DNA sammenlikninger er å visualisere hvordan sekvensen blir sammenlignet i noe som kalles DNA-oppstillinger. Se Figur/Bilde 1 for en grafisk beskrivelse av dette begrepet.
Bilde 1: Parvis sammenligning av DNA.
Unngår ikke-lignende data
 En av de første artiklene om menneske-sjimpanse DNA ble publisert av en av de tidlige pionerene for 'reassociation kinetics', Roy Britten (3). Denne artikkelen sammenlignet sekvenser fra fem ulike, store stykker av sjimpanse-DNA med tilsvarende områder i mennesket. DNA-segmentene i sjimpansen var noen av de første regionene som ble valgt til genom-sekvensering, på grunn av sin store likhet med forskjellige områder i menneskelig DNA. Det er et vanlig trick for å øke estimat på DNA-likhet. Forskere undersøker bare meget like pre-selekterte DNA-segmenter mellom to organismer. Det gjør at en lettere kan holde seg innen forventede estimater, men representerer samtidig ikke hele genomet. I 2002 var disse sekvensene nesten de eneste som var tilgjengelige. DNA-sekvens ressursene ble først produsert av en separat forskningsgruppe, basert på deres kjente, forutbestemte likhet med mennesker.
En av de første artiklene om menneske-sjimpanse DNA ble publisert av en av de tidlige pionerene for 'reassociation kinetics', Roy Britten (3). Denne artikkelen sammenlignet sekvenser fra fem ulike, store stykker av sjimpanse-DNA med tilsvarende områder i mennesket. DNA-segmentene i sjimpansen var noen av de første regionene som ble valgt til genom-sekvensering, på grunn av sin store likhet med forskjellige områder i menneskelig DNA. Det er et vanlig trick for å øke estimat på DNA-likhet. Forskere undersøker bare meget like pre-selekterte DNA-segmenter mellom to organismer. Det gjør at en lettere kan holde seg innen forventede estimater, men representerer samtidig ikke hele genomet. I 2002 var disse sekvensene nesten de eneste som var tilgjengelige. DNA-sekvens ressursene ble først produsert av en separat forskningsgruppe, basert på deres kjente, forutbestemte likhet med mennesker.
Bilde 2. En vil ikke vite av annet
Den totale sekvens-lengden for de fem ulike sjimpanse-segmentene som ble analysert av Britten var 846.016 baser. Imidlertid var bare 92% av dette likt nok med mennesker for at benyttet algoritme kunne utføre sammenligningen. 8% av DNA ble altså unntatt fra analysen. Ved å inkludere data om innsettinger og slettinger ble det rapportert en DNA-likhet på 95%. Imidlertid ville et mer nøyaktig estimat inkludere det som ble unngått, fordi det ikke hadde noen lignende motpart i mennesket. Det ville gitt et anslag for reell DNA-likhet på omkring 88%.
En annen, mye benyttet sekvensiering av sjimpanse DNA, benyttet formodentlig tilfeldige DNA-fragmenter i 300-600. base-orden (4). Disse ble sammenstilt med en tidlig versjon av menneskelig genom, der forskerne kastet ut 1/3 av sekvensen fra sjimpansen, fordi denne viste en total mangel på DNA-likhet med mennesket, og dermed ikke kunne sammenlignes (med gjeldende algoritme). Dette alene indikerer en genom-likhet på ca. 67% mellom sjimpanse og menneske. Det er et langt stykke unna de 98% som vanligvis framheves.
 Så arbeidet forskerne med disse 67% data på en høyst selektiv måte, og anskaffet bare detalj-ulikheter mellom menneske og sjimpanse for små biter av tilhørende områder, som var meget identiske. Som et resultat av denne høyst selektive prosessen, oppnådde dette endelige -håndplukkede ('cherry picked') datasettet en påstått DNA-likhet på 98,5%. I virkeligheten hadde store datamangder blitt forkastet i den hensikt å oppnå denne likheten.
Så arbeidet forskerne med disse 67% data på en høyst selektiv måte, og anskaffet bare detalj-ulikheter mellom menneske og sjimpanse for små biter av tilhørende områder, som var meget identiske. Som et resultat av denne høyst selektive prosessen, oppnådde dette endelige -håndplukkede ('cherry picked') datasettet en påstått DNA-likhet på 98,5%. I virkeligheten hadde store datamangder blitt forkastet i den hensikt å oppnå denne likheten.
Bilde 3. Det lønner seg ikke pushe fakta for langt
Dessverre ble denne bekymringsverdige teknikken alment akseptert blant forskere. Det er resultat av denne selektive forskningsprosessen som forsyner populær-pressen med det repeterende 'memet' om 98-99% DNA-likhet. Forkastelse av 'ikke-passende' data, i menneske-sjimpanse sammenlikninger, er ofte så alvorlige at selv nøkkel-data, som kunne tillate 'inside-lesere' å beregne egne estimat på total-likhet, bare blir droppet. F.eks. rapporterte en nøkkel-studie om likhet mellom menneske, sjimpanse, bavian og silkeape (5). Da var informasjon om start-punkt og spesifikke data for sammenstillingen totalt utelatt. Forfatterne oppga bare at det totalt var sammenlignet 10,6 Mb (millioner baser). Etter å ha unngått ikke-likt DNA var resultatet 98,9%. Men det var umulig å evaluere undersøkelsen, fordi detaljene var utelatt fra publikasjonen.
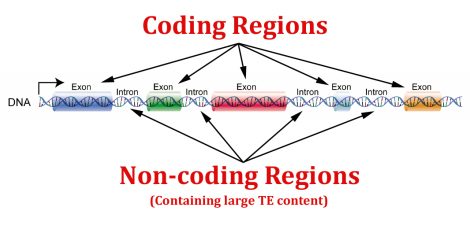
Selektiv bruk av likt kodende regioner
Et annet bekymringsverdig trekk, er at bare selekterte, høyst like proteinkodende regioner benyttes til å rapportere genom-nivåer av likhet. Det faller på egen urimelighet, siden protein-kodende sekvenser (eksoner), utgjøre mindre enn 5% av menneske genomet. Mesteparten av delen på 95% er sammensatt av ikke-kodende RNA og regulerende sekvenser (6). En kjent  studie benyttet 97 ekson-fragmenter (7). Nå er det mer enn 234.000 protein-kodende eksoner i det menneskelige genom (8), så dette er langt fra et genom-vidt utvalg. I tillegg ble eksonene i nevnte studie forutbestemt, ut fra kriteriet at de var kjent å være meget like for mennesker og sjimpanser. På grunn av en sjokkerende mangel på detaljer, er det umulig å oppnå et gyldig estimat på aktuell DNA-likhet i dette studiet.
studie benyttet 97 ekson-fragmenter (7). Nå er det mer enn 234.000 protein-kodende eksoner i det menneskelige genom (8), så dette er langt fra et genom-vidt utvalg. I tillegg ble eksonene i nevnte studie forutbestemt, ut fra kriteriet at de var kjent å være meget like for mennesker og sjimpanser. På grunn av en sjokkerende mangel på detaljer, er det umulig å oppnå et gyldig estimat på aktuell DNA-likhet i dette studiet.
Et annet lignende studie benyttet samme teknikker og igjen ble ikke data gitt for å tillate beregning av total DNA-likhet(9). Av det totale start-antallet av antall gen-sekvenser, forkastet de 33%, i et tvetydig uttalt 'meget konservativ kvalitetskontroll'. Med andre ord: de var ikke like nok og kunne ikke sammenlignes med mennesket.
Bilde 4. Omskrivninger kan nå et nivå som ligner veldig på fantasi.
Det ene interessante og repeterende faktum, som går igjen i slike undersøkelser, er at ca. 1/3 av sekvensene i sjimpansens DNA, må forkastes fordi det er for ulikt menneskelig DNA, ved å benytte standard parvis DNA-sekvens sammenlignings-algoritmer.
Unngår biologiske DNA-utvalg
 Det er ikke bare disse nevnte, tvilsomme teknikkene som benyttes. Et mye brukt magasin bruker en blanding av DNA-biblioteker for å velge stykker av sjimpanse-DNA, til å sekvensere kromosom 22 hos sjimpansen. (10). For å velge ut sjimpanse-DNA, kreves det imidlertid at fragmentene må inneholde 6-10 menneskelige DNA-markører. Enda en gang har vi en forutinntatt pre-seleksjon. Mens forskerne så etter sjimpanse DNA-fragmenter som var meget like menneskelig kromosom 22, så er det interessant at dette er det ene kromosomet i menneskelig genom som er det totalt mest like sjimpansen. De oppgir bare å benytte 82.000 baser og gir en graf som viser størrelses-fordeling, ellers ingenting.
Det er ikke bare disse nevnte, tvilsomme teknikkene som benyttes. Et mye brukt magasin bruker en blanding av DNA-biblioteker for å velge stykker av sjimpanse-DNA, til å sekvensere kromosom 22 hos sjimpansen. (10). For å velge ut sjimpanse-DNA, kreves det imidlertid at fragmentene må inneholde 6-10 menneskelige DNA-markører. Enda en gang har vi en forutinntatt pre-seleksjon. Mens forskerne så etter sjimpanse DNA-fragmenter som var meget like menneskelig kromosom 22, så er det interessant at dette er det ene kromosomet i menneskelig genom som er det totalt mest like sjimpansen. De oppgir bare å benytte 82.000 baser og gir en graf som viser størrelses-fordeling, ellers ingenting.
Bilde 5. Både eksoner og introner spiller en rolle
Røft anslag for sjimpansen
Milepel publikasjonen for menneske-sjimpanse sammenligning, var 2005 publikasjonen fra det 'the International Chimpanzee Genome Sequencing Consortium. Dette arbeidet fulgte også den etablerte trenden hvor sammenliknede data var meget selektivt utvalgt, og store mengder av ulikt DNA ble forkastet. Igjen var detaljerte deskriptive data angående undersøkelsen utelatt. likevel framheves undersøkelsen som autoritativ for å påvise likhet mellom menneske-sjimpanse DNA. Mesteparten av undersøkelsen var basert på sammenligninger som bare kan utføres dersom det er høyst identiske data-matcher (alt annet unngås). Det var en effektiv måte å forvirre og omgå faktumet at menneske-sjimpanse genom ikke på langt nær er så identiske om populær propaganda hevder.
 Ved å benytte eksisterende informasjon fra menneskelig genom-prosjekt (13), så kan en på basis av ulike statistikker i artikkelen bestemme et konservativt anslag for likhet. Forfatterne hevder: 'Beste nukleotide-sammenstilling dekker 2,4 Gb (milliarder baser), og intron-ulikhetene bellom dem er totalt ca 90Mb (millioner baser). På denne tiden var menneskelig genom anslått til å være ca. 2,85 Gb. Men hovedpoenget er at bare 2,3 Gb av sjimpanse sekvensen lot seg sammenlikne på det nøyaktige og komplette menneskelige genom på 2,85Gb. Dette arbeidet inkluderte også forkastelse av 'lav-kompleksitets sekvenser'. (DNA som er repeterende eller ikke ansett tilstrekkelig komplekst (ut fra standard algortime parametre). Ut fra et konservativt estimat (forøker verdien) kan DNA-likheten kalkuleres til ca.89%. Det er et meget forskjellig anslag enn de 98-99 som 'gullstandarden fastslår'.
Ved å benytte eksisterende informasjon fra menneskelig genom-prosjekt (13), så kan en på basis av ulike statistikker i artikkelen bestemme et konservativt anslag for likhet. Forfatterne hevder: 'Beste nukleotide-sammenstilling dekker 2,4 Gb (milliarder baser), og intron-ulikhetene bellom dem er totalt ca 90Mb (millioner baser). På denne tiden var menneskelig genom anslått til å være ca. 2,85 Gb. Men hovedpoenget er at bare 2,3 Gb av sjimpanse sekvensen lot seg sammenlikne på det nøyaktige og komplette menneskelige genom på 2,85Gb. Dette arbeidet inkluderte også forkastelse av 'lav-kompleksitets sekvenser'. (DNA som er repeterende eller ikke ansett tilstrekkelig komplekst (ut fra standard algortime parametre). Ut fra et konservativt estimat (forøker verdien) kan DNA-likheten kalkuleres til ca.89%. Det er et meget forskjellig anslag enn de 98-99 som 'gullstandarden fastslår'.
Bilde 6. Menneskelig genom -kartlagt
Senere data for sjimpanse-genomet fastslår at det er ca 8% større enn menneske-genomet. Dette samsvarer bra med tidligere studier, der forskere som nevnt kvittet seg med ca. 1/3 av dataene, som ikke var like nok til å sammenligne med valgte algoritme.
Det store ulikhets-sjokket
I løpet av noen få år etter artikkelen om sjimpanse-genomet i 2005, kom den første store innrømmelsen av ikke-likhet mellom sjimpanser og mennesker, uttrykt av en sekulær evolusjonist-gruppe (14). Det at de manipulerte og filtrerte data så mye som mulig, var med å gjøre denne innrømmelsen enda mer spektakulær. Til tross for deres forutinntatte anstrengelser, viste sluttresultatet at ingen klar sti for felles avstamning eksisterte mellom menneske eller noen annen  ape, tilfelles med en mye redusert DNA-likhet i forhold til det som tidligere var hevdet. Kanskje den beste forklaring på forskningen kan leses i den ansvarliges egne ord: "For omtrent 23% av vårt genom deler vi intet felles opphav med vår nærmest levende slektning, sjimpansen". Og: "2/3 av tilfellene resulterer i ei slektstavle der sjimpanser og mennesker ikke er hverandres nærmeste genetiske slektninger. De tilsvarende slektstavlene er inkongruente med artsstreet. I samsvar med eksperimentelle bevis , impliserer dette at det ikke finnes noe slikt som en unik evolusjonær historie for det menneskelige genom. Det ligner heller et nettverk av individuelle regioner, som følger sin eget stamtavle."
ape, tilfelles med en mye redusert DNA-likhet i forhold til det som tidligere var hevdet. Kanskje den beste forklaring på forskningen kan leses i den ansvarliges egne ord: "For omtrent 23% av vårt genom deler vi intet felles opphav med vår nærmest levende slektning, sjimpansen". Og: "2/3 av tilfellene resulterer i ei slektstavle der sjimpanser og mennesker ikke er hverandres nærmeste genetiske slektninger. De tilsvarende slektstavlene er inkongruente med artsstreet. I samsvar med eksperimentelle bevis , impliserer dette at det ikke finnes noe slikt som en unik evolusjonær historie for det menneskelige genom. Det ligner heller et nettverk av individuelle regioner, som følger sin eget stamtavle."
Bilde 7. Sagt om hodeskaller
Forurensing som leder til større likhet
En annen faktor å ta med i betraktning, er at noe av grunnen til høy likhet skyldes forurensing, både som følge av tidligere mangel på kunnskap, uhell og bevisst- i følge forskernes egne ord. Det virker som vidt spredd forurensing fra ikke-primat databaser med menneskelig DNA er et alvorlig problem, og kan utgjøre så mye som 10% (15). Menneskelig forurensing av primat (ape)-databaser er et vanskelig og høyst subjektivt problem. Da sjimpanse-genomet ble sekvensiert, hadde en ikke fått med seg det aller nyeste om spredning av menneskelig DNA-forurensing. Forurensingsproblematikk i laboratoriet blir ytterligere aksentuert, ved bruk av menneskelige DNA-sekvenser til å konstruere, samle og karakterisere/kommentere sjimpanse-DNA, basert på evolusjonære forutsetninger.
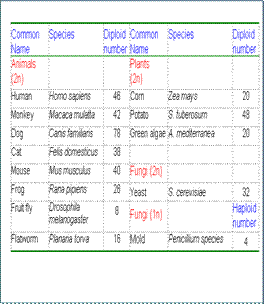 Bilde 8. Likheten ikke så overveldende
Bilde 8. Likheten ikke så overveldende
Faktisk ble 'elektronisk-forurensing' introdusert med hensikt i løpet av samling og kommentering av sjimpanse-genomet. I en nylig web-side fra en av verdens ledende DNA-analyse laboratorier (www.ensembl.org), så ga en side med tittelen 'Sjimpanse genbygging' flg. informasjon (16): " Som følge av et lite antall proteiner, så ble et tilleggslag av genstrukturer lagt til ved projisering av menneskelige gener. Høy-kvalitets beskrivelse av menneskelig genom og høy grad av samsvar mellom menneske og sjimpanse-genom, setter oss i stand til å identifisere gener i sjimpansen, ved overførsel av menneskelige gener til samsvarende steder for sjimpansen." Og igjen: ".. små innsettinger/slettinger som ødelegger lese-rammen til resultatet blir korrigert for ved å sette inn 'ramme-skift' introner inn i strukturen."
Det er ganske oppsiktsvekkende utsagn sitert direkte fra folk som var ansvarlige for å produsere sjimpanse-genomet. De la til menneskelige gen-sekvenser -som ikke eksisterte, til sjimpanse-DNA. Og de korrigerte til og med innsettinger og slettinger for å gjøre oppsettet mer menneske-likt. Når noen vil laste ned sjimpanse-DNA, må de forstå at det med vilje er forurenset med menneskelig DNA, basert på evousjonære forutsetninger, som gjorde det mer menneskelikt enn det i virkeligheten var.
Konklusjon: menneske og sjimpanse-DNA, ikke så like når det kommer til stykket.
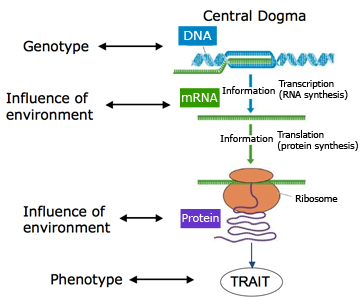 Nesten alle sekulære forskningsrapporter om menneske-sjimpanse DNA likheter, utelater betydelige mengder av data som ikke passer med hverandre. Disse områdene i kromosomer representerer ofte menneskelig DNA, fraværende i sjimpanser, eller sjimpanse-DNA fraværende i mennesker. Mange offentlige forskningsartikler inkluderer ikke nok data til å tillate en kritisk leser muligheten til å beregne hvor mye ulikhet som fantes før de endelige, filtrerte tallene blir oppgitt. I forhold til et aktuelt estimat av sjimpanse-menneske likhet, er det sikkert å si at det ikke er mer enn 86-89% som er like.
Nesten alle sekulære forskningsrapporter om menneske-sjimpanse DNA likheter, utelater betydelige mengder av data som ikke passer med hverandre. Disse områdene i kromosomer representerer ofte menneskelig DNA, fraværende i sjimpanser, eller sjimpanse-DNA fraværende i mennesker. Mange offentlige forskningsartikler inkluderer ikke nok data til å tillate en kritisk leser muligheten til å beregne hvor mye ulikhet som fantes før de endelige, filtrerte tallene blir oppgitt. I forhold til et aktuelt estimat av sjimpanse-menneske likhet, er det sikkert å si at det ikke er mer enn 86-89% som er like.
Bilde 9. Fra DNA til ferdig dyr
På bakgrunn av temmelig lik kroppsbygning og biokjemi i cellene, er det å forvente en relativt stor del av DNA-likhet mellom artene, spesielt i forhold til protein-kodende regioner i DNA. Felles bruk er et kjennetegn på konstruerte systemer. Imidlertid er evolusjonister oppsatt på å vise at sjimpanser bare er noen få basepar unna å være mennesker. Realiteten er at mennesker ikke er aper. De atskiller seg betydelig fra slike, noe stadig mer omfattende DNA-bevis framhever.
Utvalg av stoff og bilder ved Asbjørn E. Lund
.